فائزه حجتی | بهمن ۲۷, ۱۳۹۵ | 11 دیدگاه
در مبحث تحلیل عاملی به موضوعات زیر پرداخته شده است:
تحلیل عاملی از جمله روشهای چند متغیره است که در آن متغیرهای مستقل و وابسته مطرح نیست، زیرا این روش جزء تکنیکهای هم وابسته محسوب میگردد و کلیه متغیرها نسبت به هم وابستهاند. تحلیل عاملی نقش بسیار مهمی در شناسایی متغیرهای مکنون یا همان عاملها از طریق متغیرهای مشاهده شده دارد. عامل (factor) متغیر جدیدی است که از طریق ترکیب خطی مقادیر اصلی متغیرهای مشاهده شده برآورد میشود. روﺵ ﺗﺤﻠﻴﻞ عاملی ﺑﺮﺍﻱ ﺳﺎﺧﺖ ﺁﺯﻣـﻮﻥﻫـﺎ ﺍﻭﻟـﻴﻦ ﺑـﺎﺭ ﺗﻮﺳـﻂ ﭼﺎﺭﻟﺰ ﺍﺳﭙﻴﺮﻣﻦ ﺑﻪ ﻛﺎﺭ ﺑﺮﺩﻩ ﺷـﺪﻩ ﺍﺳـت. ﺑـﻪ ﻫﻤـﻴﻦ ﺩﻟﻴـﻞ ﻭﻱ ﺭﺍ ﻣﺒﺘﻜـﺮ ﺭﻭﺵ ﺗﺤﻠﻴــﻞ عاملی ﻣــیﻧﺎﻣﻨـﺪ.
ﺗﺤﻠﻴــﻞ عاملی ﻳﻜــﻲ ﺍﺯ ﺭﻭﺵﻫﺎﻱ ﭘﻴﺸﺮﻓﺘﻪ ﺁﻣﺎﺭﻱ ﺍﺳﺖ که بر مبنای آن متغیرها به گونهای دسته بندی میشوند که در نهایت به دو یا چند عامل که همان مجموعه متغیرها هستند، محدود میگردند، بنابراین هر عامل را میتوان متغیری ساختگی یا فرضی در نظر گرفت که از ترکیب چند متغیر که از وجوهی به هم شباهت دارند، ساخته شده است. دادههای اولیه برای تحلیل عاملی، ماتریس همبستگی بین متغیرها است و متغیرهای وابسته از پیش تعیین شدهای ندارد.
رویکردهای تحلیل عاملی را میتوان به دو دسته کلی تقسیم کرد:
اینکه کدام یک از این دو روش باید در تحلیل عاملی به کار رود مبتنی بر هدف تحلیل دادههاست. تمایز مهم روشهای تحلیل عاملی اکتشافی و تاییدی در این است که روش اکتشافی با صرفهترین روش تبیین واریانس مشترک زیربنایی یک ماتریس همبستگی را مشخص میکند. در حالی که روشهای تاییدی (آزمون فرضیه) تعیین میکنند که دادهها با یک ساختار عاملی معین (که در فرضیه آمده) هماهنگ هستند یا نه. به طور کلی، تحلیل عاملی اکتشافی (EFA) ممکن است در حوزههای تحقیقاتی کمتر بالغ که در آن سئوالات اندازهگیری اساسی هنوز حل نشده انتخاب بهتری باشد. این روش همچنین در مقایسه با CFA نیاز به پیشفرضهای کمتری دارد. در پژوهشهای ارزیابی، EFA معمولاً در مطالعات اولیه و CFA در مطالعات بعدی همان حوزه استفاده شود.
در شکل ۱ دو مدل اندازه گیری فرضی برای ۶ شاخص و ۲ عامل ارائه و با علائمSEM نشان داده شده است. در این شکل مربع یا مستطیل برای نشان دادن متغیرهای مشاهده، بیضی یا دایره برای متغیرهای پنهان و یا عبارات خطا، پیکانهای یک سویه (→) برای اثرات مستقیم از متغیرهای علت به متغیرهای تحت تاثیر آنها، پیکانهای دوسویه منحنی شکل که از یک متغیر خارج و به همان متغیر وارد میشوند، برای عاملها یا عبارات خطا؛ و خطوط منحنی با پیکان دوسویه برای نشان دادن کوواریانس بین دو عامل یا دو عبارت خطا (در راه حل استاندارد نشده، کوواریانس و در راه حل استاندارد، همبستگی) میباشد.
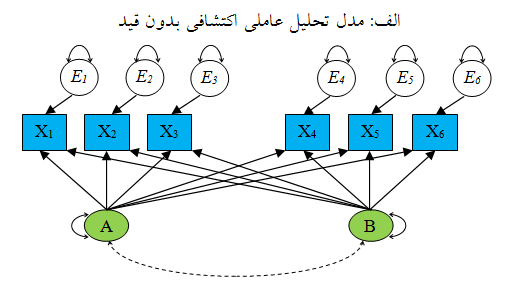
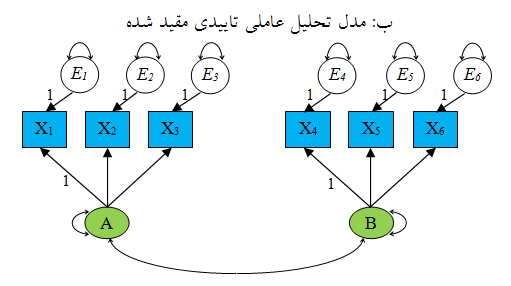
شکل ۱: یک مدل تحلیل عاملی اکتشافی و یک مدل عاملی تاییدی برای ۶ شاخص و ۲ عامل
دﺭ ﺭﻭﺵ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺍﻛﺘﺸﺎﻓﻲ ﻋﻤﺪﻩﺗـﺮﻳﻦ ﻫـﺪﻑ ﻣـﺸﺨﺺ ﻛـﺮﺩﻥ ﺣﺪﺍﻗﻞ ﺗﻌﺪﺍﺩ ﻋﺎﻣﻞﻫﺎ ﺑﻪ ﻣﻨﻈﻮﺭ ﺑﺮﺁﻭﺭﺩ ﻫﻤﺒﺴﺘﮕﻲ ﺑﻴﻦ ﺁﺯﻣـﻮﻥﻫـﺎ ﺍﺳﺖ. ﺩﺭ ﺍﻳﻦ ﺭﻭﺵ ﻓﺮﺽﺑﺮ ﺍﻳﻦ ﺍﺳﺖ ﻛﻪ ﻫﺮ ﭼﻪ ﻣﻘـﺪﺍﺭ ﻋﺎﻣـﻞﻫـﺎ ﺑﺮﺍﻱ ﺑﺮﺁﻭﺭﺩ ﻫﻤﺒﺴﺘﮕﻲ ﺑﻴﻦ ﮔﺮﻭﻫﻲ ﺍﺯﺁﺯﻣﻮﻥﻫﺎ ﻛﻢﺗﺮ ﺑﺎﺷﺪ، ﺗﻔﺴﻴﺮ ﺍﻳﻦ ﻋﺎﻣﻞﻫﺎ ﺍﺯ ﻟﺤﺎﻅ ﺭﻭﺍﻧﺸﻨﺎﺳﻲ ﻧﻴﺰ ﺳﺎﺩﻩﺗﺮ ﺧﻮﺍﻫﺪ ﺑﻮﺩ. ﻋـﻼﻭﻩ ﺑـﺮ این دﺭ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺍﻛﺘﺸﺎﻓﻲ ﺣﺪﺍﻗﻞ ﺗﻌﺪﺍﺩ ﻋﺎﻣﻞﻫﺎ ﺟﻬﺖ ﺑﺮﺁﻭﺭﺩ ﻭﺍﺭﻳﺎﻧﺲ ﻣﺸﺘﺮﻙ ﺑﻴﻦ ﻣﺠﻤﻮﻋـهﺍی ﺍﺯ ﻗـﺴﻤﺖﻫـﺎ ﺑـﻪ ﻛـﺎﺭ ﺑـﺮﺩﻩ ﻣﻲﺷﻮﺩ.
تحلیل اکتشافی وقتی به کار میرود که پژوهشگر شواهد کافی قبلی و پیش تجربی برای تشکیل فرضیه درباره تعداد عاملهای زیربنایی دادهها نداشته و به واقع مایل باشد درباره تعیین تعداد یا ماهیت عاملهایی که همپراشی بین متغیرها را توجیه میکنند، دادهها را بکاود. بنابراین تحلیل اکتشافی بیشتر به عنوان یک روش تدوین و تولید تئوری و نه یک روش آزمون تئوری در نظر گرفته میشود. یعنی تحلیل اکتشافی میتواند ساختارساز، مدل ساز یا فرضیه ساز باشد.
علاوه براین، تحلیل عاملی مستلزم سئوالهایی درباره روایی است. در فرایند تعیین این مطلب که آیا عاملهای شناخته شده با یکدیگر همبسته هستند یا نه، تحلیل اکتشافی به این پرسش روایی سازه جواب میدهد که آیا نمرههای تست آنچه را تست باید بسنجد، اندازه میگیرد؟ ﺍﻭﻟﻴﻦ ﻗﺪﻡ ﻭ ﺩﺭ ﻋﻴﻦ ﺣﺎﻝ ﻣﻬﻢﺗﺮﻳﻦ ﻣﺮﺣﻠﻪ ﺑﺮﺍﻱ ﺳـﺎﺧﺖ ﻳـﻚ ﻣﻘﻴﺎﺱ ﺍﻧﺪﺍﺯﻩﮔﻴﺮﻱ (تست) ﻧﻮﺷﺘﻦ آیتمﻫﺎﻳﻲ ﺍﺳﺖ ﻛﻪ ﺑﺎ ﺳﺎﺯﻩﻱ ﻣﻮﺭﺩ ﻧﻈﺮ ﻫﻤﺎﻫﻨﮓ ﺑﺎﺷﻨﺪ. ﻣﺠﻤﻮﻋﻪ ﺁﻳﺘﻢها ﻣﻲﺗﻮﺍﻧـﺪ ﻣﺒﻨﺎﻱ ﺗﺌﻮﺭﻳﻚ ﻳﺎ ﻏﻴﺮ ﺗﺌﻮﺭﻳﻚ ﺩﺍﺷﺘﻪ ﺑﺎﺷﺪ. ﺍﻣﺎ ﺁﻥ ﭼﻪ ﺑﺮﺍﻱ ﺗﺤﻠﻴـﻞ ﻋﺎﻣﻠﻲ ﺑﺴﻴﺎﺭ ﻣﻨﺎﺳﺐ ﺍﺳﺖ، ﻣﺠﻤﻮﻋﻪ ﺁﻳﺘﻤﻲ ﺍﺳـﺖ ﻛـﻪ ﻫﻤـﻪ ﺍﺑﻌـﺎﺩ ﻧﻈﺮﻱ ﻭ ﺗﺠﺮﺑﻲ ﺻﻔﺘﻲ ﻛﻪ ﻣﻲﺧﻮﺍﻫﻴﺪ ﺑﺮﺍﻱ ﺁﻥ ﻣﻘﻴﺎس ﺑﺴﺎﺯﻳﺪ، ﺩﺭ ﺑﺮ ﺑﮕﻴﺮﺩ. ﺑﺮ ﻫﻤﻴﻦ ﺍﺳﺎﺱ ﻫﺮ ﭼﻪ ﻣﺠﻤﻮﻋﻪ ﺁﻳﺘﻢ ﺩﻗﻴﻖﺗﺮ ﻭ ﻛﺎﻣﻞﺗﺮ باشد، مقیاﺱ ﺍﻧﺪﺍﺯﻩﮔﻴﺮﻱ ﻣﻌﺘﺒﺮتری ﺣﺎﺻﻞ ﺧﻮﺍﻫﺪ ﺷﺪ. ﻟﺬﺍ ﻣﻄﺎﻟﻌﻪ ﺩﻗﻴﻖ ﻭ ﻛﺎﻣﻞ ﺑﺮﺍﻱ ﺗﻬﻴﻪ ﻳﻚ ﻣﺠﻤﻮﻋﻪ ﺁﻳﺘﻢ ﺟﺎﻣﻊ ﺑﺮﺍﻱ ﺳﺎﺧﺖ ﻣﻘﻴﺎﺱ ﺍﻫﻤﻴﺖ ﺑﻪ ﺳﺰﺍﻳﻲ ﺑﺮﺧﻮﺭﺩﺍﺭ ﺍﺳﺖ.
در تحلیل عاملی آیتمهایی که با یک عامل همبستگی بالایی داشته باشند، در آن عامل قرار میگیرند. همبستگی بین هر آیتم با هر عامل از طریق بار عاملی نشان داده میشود. معمولا ضرایب بالاتر از ۰٫۳۰ و گاه بالاتر از ۰٫۴۰ در تعریف عاملها مهم و بامعنا تلقی شده و ضرایب کمتر از این حدود را به عنوان صفر (مولفه تصادفی) در نظر گرفتهاند. البته هر چه بار عاملی یک آیتم زیادتر باشد، نفوذ آن آیتم در تبیین ماهیت مولفه مورد نظر بیشتر است.
دﺭﺻﻮﺭتیﻛﻪ ﺩﺭ ﺧﺮﻭﺟﻲﻫﺎﻱ ﻛﺎﻣﭙﻴﻮﺗﺮ ﺑـﺮﺍﻱ ﻳﻚ ﻣﺎﺩﻩ، ﻭﺯﻥﻫﺎﻱ ﻋﺎﻣﻠﻲ ﺑﻴﺶ ﺍﺯ ﻳﻚ ﻋﺎﻣﻞ ﺩﺍﺩﻩ ﺷﺪﻩ ﺑﺎﺷـﺪ، ﺍﻳـﻦ ﺣﺎﻟﺖ ﺑﻪ ﻣﻌﻨﻲ ﺍﻳﻦ ﺍﺳﺖ ﻛﻪ ﻣﺤﺘﻮﺍﻱ ﺁﻥ آیتم ﻣﻲﺗﻮﺍﻧﺪ ﺩﺭ ﺑﻴﺶ ﺍﺯ ﻳﻚ ﻋﺎﻣﻞ ﻗﺮﺍﺭ ﮔﻴﺮﺩ. ﺍﻣﺎ ﺍﺯ ﺁﻥﺟﺎﻳﻲ ﻛﻪ ﻫﺮ آیتم ﺻﺮﻓﺎ ﻣﻲﺗﻮﺍﻧﺪ ﺩﺭ ﻳﻚ ﻋﺎﻣﻞ ﻗﺮﺍﺭ ﮔﻴﺮﺩ، ﺩﺭ ﺍﻧﺘﺨﺎﺏ ﻋﺎﻣﻞ ﺁﻥ، ﺑﺎﻳـﺪ ﺑـﺎ ﺗﻮﺟـﻪ ﺑـﻪ ﻭﺯﻥ عاملی اقدام نمود. به این صورت که وزن عاملی با هر عامل که بیشتر بود، باید آیتم مورد نظر در آن عامل قرار گیرد.
اﺯ ﻟﺤﺎﻅ ﻧﻈﺮﻱ ﻧﻤﺮﻩ ﻛﻞ ﻫﺮ ﻋﺎﻣﻞ ﺑﺎﻳﺪ ﻫﻤﺒﺴﺘﮕﻲ ﻣﻌﻨﺎﺩﺍﺭﻱ ﺑﺎ ﻧﻤﺮﻩ ﻛﻞ ﺁﺯﻣﻮﻥ ﺩﺍﺷﺘﻪ ﺑﺎﺷﺪ. ﺑﺮﺭﺳﻲ ﺍﻳﻦ ﺷﺮﺍﻳﻂ ﺍﺯ ﻃﺮﻳﻖ ﻣﺎﺗﺮﻳﺲ ﻫﻤﺒﺴﺘﮕﻲ ﻋﺎﻣﻞﻫﺎ ﺑﺎ ﻳﻜﺪﻳﮕﺮ ﻭ ﻧﻤﺮﻩ ﻛﻞ ﺁﺯﻣﻮﻥ ﺻﻮﺭﺕ ﻣﻲگیرﺩ. ﻣﺎﺗﺮﻳﺲ ﻫﻤﺒﺴﺘﮕﻲ ﺩﺭ ﺍﻳﻦ ﺷﺮﺍﻳﻂ ﺍﻃﻼﻋﺎﺕ ﺑﺴﻴﺎﺭ ﻣﻨﺎﺳﺒﻲ ﺍﺯ ﺳﺎﺧﺘﺎﺭ ﺩﺭﻭﻧﻲ ﺁﺯﻣﻮﻥ ﻧﻴﺰ ﺩﺭ ﺍﺧﺘﻴﺎﺭ ﺁﺯﻣﻮﻥ ﺳﺎﺯ ﻗﺮﺍﺭ ﻣﻲﺩﻫﺪ. ﺍﮔﺮ ﻋﺎﻣﻞ ﺑﺎ ﻧﻤﺮﻩ ﻛﻞ ﺁﺯﻣﻮﻥ، ﻫﻤﺒﺴﺘﮕﻲ ﻣﻌﻨﺎﺩﺍﺭﻱ ﻧﺪﺍﺷﺘﻪ ﺑﺎﺷﺪ ﺑﻪ ﺍﻳﻦ ﻣﻌﻨﻲ ﺍﺳﺖ ﻛﻪ ﺳﻬﻤﻲ ﺩﺭ ﺍﻳﺠﺎﺩ ﻭﺍﺭﻳﺎﻧﺲ ﺁﺯﻣﻮﻥ ﻧﺪﺍﺭﺩ. ﺑﻪ ﻫﻤﻴﻦ ﺟﻬﺖ ﻧﻤﻲﺗﻮﺍﻧﺪ ﻋﺎﻣﻞ ﻣﻨﺎﺳﺒﻲ ﺗﺸﺨﻴﺺ ﺩﺍﺩﻩ ﺷﻮﺩ. ﻫﺮﭼﻪ ﻫﻤﺒﺴﺘﮕﻲ ﻋﺎﻣﻞ ﺑﺎ ﻧﻤﺮﻩ ﻛﻞ ﺁﺯﻣﻮﻥ ﺑﺎﻻﺗﺮ ﺑﺎﺷﺪ، ﻧﺸﺎﻥ ﺩﻫﻨﺪﻩ ﺍﻳﻦ ﻣﻔﻬﻮﻡ ﺍﺳﺖ ﻛﻪ ﺩﺭ ﺍﻳﺠﺎﺩ ﻭﺍﺭﻳﺎﻧﺲ ﺁﺯﻣﻮﻥ ﺳﻬﻢ ﺑﻪ ﺳﺰﺍﻳﻲ ﺩﺍﺭﺩ. ﺑﻪ ﺍﻳﻦ ﺗﺮﺗﻴﺐ ﺍﺯ ﻃﺮﻳﻖ ﻣﺎﺗﺮﻳﺲ ﻫﻤﺒﺴﺘﮕﻲ ﻫﺮ ﻋﺎﻣﻞ ﺑﺎ ﻳﻜﺪﻳﮕﺮ ﻭ ﻧﻤﺮﻩ ﻛﻞ، ﻋﻼﻭﻩ ﺑﻪ ﺑﺮﺭﺳﻲ ﺳﺎﺧﺘﺎﺭ ﺩﺭﻭﻧﻲ ﭘﺮﺳﺸﻨﺎﻣﻪ ﻣﻲﺗﻮﺍﻥ ﺑﻪ ﺑﺮﺭﺳﻲ ﻭﺿﻌﻴﺖ ﻋﺎﻣﻞﻫﺎﻱ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺩﺭ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﭘﺮﺩﺍﺧﺖ.
ﺿﺮﻳﺐ ﺍﺷﺘﺮﺍﻙ ﺑﻪ ﻧﻮﻋﻲ ﻣﻌﺮﻑ ﻫﻤﺒﺴﺘﮕﻲ ﺑﻴﻦ ﺁﻳـﺘﻢ ﺑـﺎ ﺳـﺎﻳﺮ ﺁﻳﺘﻢﻫﺎﻱ ﻋﺎﻣﻞ ﻣﻮﺭﺩ ﻧﻈﺮ ﻧﻴﺰ ﻣـﻲ ﺑﺎﺷـﺪ. در برﺭﺳﻲ ﺿﺮﻳﺐ ﺍﺷﺘﺮﺍﻙ ﺁﻳﺘﻢﻫﺎﻱ ﻫـﺮ ﻋﺎﻣـﻞ، ﺍﮔـﺮ ﺁیتمی ﺿﺮﻳﺐ ﺍﺷﺘﺮﺍﻙ ﭘﺎﺋﻴﻦ ﺩﺍﺷﺘﻪ ﺑﺎﺷﺪ ﺑﻪ ﻣﻌﻨﺎﻱ ﺍﻳﻦ ﺍﺳﺖ ﻛـﻪ ﺍﻭﻻ ﺑـﺎ ﺁﻳﺘﻢﻫﺎﻱ ﺩﻳﮕﺮ ﺁﻥ ﻋﺎﻣﻞ ﻫﻤﺒﺴﺘﮕﻲ ﭘﺎﺋﻴﻦ ﺩﺍﺭﺩ ﻭ ﺛﺎﻧﻴﺎ ﺳﻬﻢ ﺑﺎﺭﺯﻱ ﺩﺭ ﻭﺍﺭﻳﺎﻧﺲ ﻋﺎﻣﻞ ﻣﺸﺘﺮﻙ ﻣﻮﺭﺩ ﻧﻈﺮ ﻧﺪﺍﺭﺩ. ﺍﺯ ﺍﻳﻦ ﺭﻭ ﻧﻤﻲﺗﻮﺍﻧﺪ ﺑـﻪ ﻋﻨﻮﺍﻥ ﻳﻚ ﺁﻳﺘﻢ ﻣﻨﺎﺳﺐ ﺩﺭ ﻋﺎﻣﻞ ﺑـﺎﻗﻲ ﺑﻤﺎﻧـﺪ. ﺑﻨـﺎﺑﺮﺍﻳﻦ ﻫـﺮ ﭼـﻪ ﺿﺮﻳﺐ ﺍﺷﺘﺮﺍﻙ ﻳﻚ آیتم ﺑﻪ ﻳﻚ ﻧﺰﺩﻳﻚﺗﺮ ﺑﺎﺷﺪ، آیتم ﻣﻨﺎﺳـﺒﻲ ﺩﺭ ﺗﺒﻴﻴﻦ ﻋﺎﻣﻞ ﻣﻮﺭﺩ ﻧﻈﺮ ﺷﻨﺎﺧﺘﻪ ﻣﻲﺷﻮﺩ. ﺑﺎ ﺗﻮﺟﻪ ﺑـﻪ ﺍﻳـﻦﻛـﻪ ﻫـﺮ آیتم ﺻﺮﻓﺎ ﺑﺎﻳﺪ ﺩﺭ ﻳﻚ ﻋﺎﻣﻞ ﻗﺮﺍﺭ ﮔﻴﺮﺩ، ﺑﻪ ﻫﺮ ﻣﻴﺰﺍﻧـﻲ ﻛـﻪ ﺿـﺮﻳﺐ ﺍﺷﺘﺮﺍﻙ ﺁﻥ ﺁﻳﺘﻢ ﺑﻪ ﻳﻚ ﻧﺰﺩﻳﻚﺗﺮ ﺑﺎﺷﺪ ﺑﻪ ﻫﻤﻴﻦ ﺟﻬﺖ ﺑﻴـﺸﺘﺮﻳﻦ ﺳﻬﻢ ﺭﺍ ﺩﺭ ﻭﺍﺭﻳﺎﻧﺲ ﻋﺎﻣﻞ ﻣﺸﺘﺮﻙ ﻋﺎﻣﻞ ﺍﻳﻔﺎ ﻣﻲ ﻛﻨﺪ.
برای ارزیابی توانایی عاملی دادهها دو شاخص آماری توسط SPSS ایجاد میشود:
شاخص کایزر- مایر – الکین (KMO) ﻣـﺸﺨﺺ میکند ﻛـﻪ ﺁﻳـﺎ ﺗﺤﻠﻴــﻞ ﻋــﺎﻣﻠﻲ بر ﺭﻭﻱ دادهﻫــﺎﻱ ﺟﻤــﻊ ﺁﻭﺭﻱ ﺷــﺪﻩ ﻗﺎﺑﻞ ﺍﺟﺮﺍ ﻣﻲﺑﺎﺷﺪ. KMO شدت ﻫﻤﺒﺴﺘﮕﻲهای متقابل ﺑﻴﻦ سئوالها یا متغیرها را بررسی میکند. چنانچه تعداد همبستگیهای بالاتر از ۰٫۳ کم باشد، تحلیل عاملی مناسب نخواهد بود. ﺣﺪﺍﻗﻞ KMO ﺍﺯ ﻃﺮﻑ ﻣﺘﺨﺼﺼﺎﻥ ﻣﺘﻔﺎﻭﺕ ﺑﻴﺎﻥ ﺷـﺪﻩ ﺍﺳـﺖ. این شاخص در دامنه صفر تا یک قرار دارد اگر مقدار شاخص نزدیک به یک باشد، داده های مورد نظر برای تحلیل عاملی مناسب هستند. کایزر (١٩٧٧) ﺣـﺪﺍﻗﻞ KMO ﺭﺍ ۰٫۶۰ ﺗﻌﻴﻴﻦ ﻣﻲﻛﻨﺪ ﺑﻪ ﻃـﻮﺭﻱ ﻛـﻪ ﺍﺟـﺮﺍﻱ ﺗﺤﻠﻴـﻞ ﻋـﺎﻣﻠﻲ ﺭﺍ ﺩﺭ ﺻﻮﺭﺗﻲ ﺑﺪﻭﻥ ﻣﺎﻧﻊ ﻣﻲﺩﺍﻧﺪ ﻛﻪ ۰٫۶۰≤ KMO ﺑﺎﺷﺪ.
ﺩﻭﻣﻴﻦ ﺁﺯﻣﻮﻥ ﺗﺎﺋﻴﺪﻱ ﻛﻪ ﻣـﻲﺑﺎﻳـﺴﺖ ﻗﺒـﻞ ﺍﺯ ﺍﺟـﺮﺍﻱ ﺩﺳـﺘﻮﺭ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺑﻪ ﻛﺎﺭ ﮔﺮﻓﺘﻪ ﺷﻮﺩ، ﺁﺯﻣﻮﻥ ﻛﺮﻭﻳﺖ ﺑﺎﺭﺗلت اﺳﺖ. ﻳﻜﻲ ﺍﺯ ﻣﻔﺮﻭﺿﻪﻫﺎﻱ ﺍﺳﺎﺳﻲ ﺩﺭ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺍﻳﻦ ﺍﺳﺖ ﻛﻪ ﺑﻴﻦ ﻣﺘﻐﻴﺮﻫﺎ ﺑﺎﻳﺪ ﻫﻤﺒﺴﺘﮕﻲ ﻭﺟـﻮﺩ ﺩﺍﺷـﺘﻪ ﺑﺎﺷـﺪ. ﺍﮔـﺮ ﻣﺘﻐﻴﺮﻫـﺎ ﻣﺴﺘﻘﻞ ﺍﺯ ﻳﻜﺪﻳﮕﺮ ﺑﺎﺷﻨﺪ ﺑﻪ ﻛﺎﺭﮔﻴﺮﻱ ﻣﺪﻝ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﻣﻨﺎﺳـﺐ ﻧﻴــﺴﺖ. ﺁﺯﻣﻮﻥ ﻛﺮﻭﻳﺖ ﺑﺎﺭﺗلت به ارزیابی این سوال میپردازد: ماتریس همبستگی که پایه تحلیل عاملی قرار میگیرد، در جامعه برابر صفر است یا خیر. فرض صفر به صورت Ho:ρij = o میباشد.
١ ـ ﺍﮔﺮ Ho ﺩﺭ ﺁﺯﻣﻮﻥ ﺁﺯﻣﻮﻥ ﻛﺮﻭﻳﺖ ﺑﺎﺭﺗلت ﺭﺩ ﺷود (یعنی p ≤α باشد)، اجرای ﺗﺤﻠﻴـﻞ ﻋﺎﻣﻠﻲ ﻣﻮﺭﺩ ﺗﺎیید ﺍﺳﺖ.
٢ ـ ﺍﮔﺮ Ho ﺩﺭ ﺁﺯﻣﻮﻥ ﺁﺯﻣﻮﻥ ﻛﺮﻭﻳﺖ ﺑﺎﺭﺗلت ﺭﺩ ﻧﺸود (یعنی p >α باشد)، ﺩﻟﻴﻠـﻲ ﺑـﺮﺍﻱ اجرای ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﻭﺟﻮﺩ ﻧﺪﺍﺭﺩ.
نکته: α سطح خطا میباشد که معمولاً ۰٫۰۵ در نظر گرفته میشود.
استخراج عاملها شامل مشخص کردن کمترین تعداد عاملهایی است که میتوان برای بهترین بازنمایی همبستگیهای متقابل بین مجموعه متغیرها به کار برد. روشهای مختلفی برای استخراج عاملها وجود دارد که متداولترین آنها عبارتند از:
ﺗﺤﻠﻴﻞ ﻣﻮﻟﻔﻪ ﺍﺻﻠﻲدر فرایند استخراج بر روی قطر اصلی ماتریس همبستگی عدد ۱ را قرار میدهد. ﺩﺭ ﺭﻭﺵ ﺗﺤﻠﻴﻞ ﻣﻮﻟﻔﻪ ﺍﺻﻠﻲ ﺯﻣﺎﻧﻲکه ﻗﻄﺮ ﻣﺎﺗﺮﻳﺲ ﻫﻤﺒﺴﺘﮕﻲ ﺗﻐﻴﻴﺮ ﻧﻜﻨﺪ، ﻣﻮﻟﻔـهﻫـﺎﻱ ﺍﺻـﻠﻲ ﻛـﻪ ﺑـﻪ عنوان ﻣﻌـﺎﺩﻟﻪﻫﺎﻱ ﺭﻳـﺎﺿﻲ ﻣﺘﻐﻴﺮﻫﺎﻱ ﺍﺻﻠﻲ ﺗﻌـﺮﻳﻒ ﺷـﺪﻩﺍﻧـﺪ، ﺍﺳﺘﺨﺮﺍﺝ ﻣﻲﮔﺮﺩﺩ. این ﺭﻭﺵ ﺑﻪ نسبت ﺳﺎﻳﺮ ﺭﻭﺵﻫﺎﻱ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ، ﺯﻣﺎﻥ کمترﻱ ﻧﻴـﺎﺯ ﺩﺍﺭﺩ ﻭ ﺑﺮ ﺍﺳـﺎﺱ ﺁﻥ ﻫـﺮ ﻣﺘﻐﻴـﺮﻱ ﻣـﻲﺗﻮﺍﻧـﺪ ﺑـﻪ n ﻣﻮﻟﻔـﻪ ﺗﺠﺰﻳـﻪ ﺷـﻮﺩ ﻭ پیشﺑﻴﻨﻲ ﺩﻗﻴﻘﻲ ﺍﺯ ﺍﻳﻦ ﻣﻮﻟﻔﻪ ﺑﻪ ﻋﻤﻞ ﺁﻭﺭﺩ.
این دو روش تفاوتهای خارج قطری بین ماتریس همبستگیهای مشاهده شده و باز تولید شده را به حداقل میرسانند. تفاوت این دو روش در این است که کمترین ﻣﺠﺬﻭﺭﺍﺕ ﺗﻌﻤﻴﻢ ﻳﺎﻓﺘـﻪ به متغیرهایی که ارتباط قوی تری با سایر متغیرها دارند (متغیرهایی که اشتراک بالا دارند)، وزن بیشتری میدهد، در حالیکه روش کمترین ﻣﺠﺬﻭﺭﺍﺕ ﻏﻴﺮﻭﺯﻧﻲ به همه متغیرها وزن یکسان میدهد.
این روش نه تنها در تحلیل عاملی اکتشافی بلکه در تحلیل عاملی تاییدی نیز پرکاربردترین روش است. این روش به جای بازتولید دادههای نمونه میکوشد با استفاده از دادههای نمونه به طور مستقیم ماتریس کوواریانس جامعه را برآورد کند. برآورد بهتر پارامترهای جامعه به نتایج تکرارپذیرتری منجر خواهد شد.
روش مذبور، روش عاملهای اصلی نیز نامیده میشود، در فرایند استخراج از برآورد اشتراکات (اندازه واریانس مشترک) در قطر ماتریس استفاده میکند و همین وجه تمایز آن با روش تحلیل مولفه اصلی میباشد.
عاملیابی آلفا نیز با برآورد اشتراک در قطر ماتریس اغاز میشود. راهبرد استخراج آن برای بیشینه ساختن اعتبار عاملها (که با ضریب آلفای کرونباخ تعریف میشود) طراحی شده است.
اگر پژوهشگر قصد پیش بینی و برآورد بیشینه واریانس متغیر وابسته را در نظر دارد، مؤلفه اصلی به دلیل جذب بیشترین مقدار واریانس مشترک و اختصاصی مقدم است.
زمانی که متغیرهای تحقیق فاصلهای هستند، روشهای ﺑﻴﺸﻴﻨﻪ ﺍﺣﺘﻤﺎﻝ و ﻋﺎﻣﻞﻳﺎﺑﻲ ﻣﺤﻮﺭ ﺍﺻﻠﻲ متداولتر هستند. اگر توزیع دادهها تقریباً نرمال باشند، روش ﺑﻴﺸﻴﻨﻪ ﺍﺣﺘﻤﺎﻝ بهترین انتخاب است.
بدون شک از لحاظ نظری تحلیل عوامل با روش های حداکثر درست نمایی و عاملیابی محور اصلی جهت استخراج عامل نسبت به روش مؤلفه اصلی دقیقتر است اما، هر چه تعداد متغیرهای دخیل در تحلیل و وزن بار عاملی این متغیرها بیشتر باشد تفاوت میان نتایج شیوه های استخراج عوامل کاهش پیدا می کند.
برای انتخاب تعداد عاملها معیارهای مختلفی وجود دارد که ممکن است هر یک از آنها نتایج متفاوتی را به همراه داشته باشند. از اینرو باید نتایج مختلف را با هم مقایسه کنیم تا به نتیجهگیری درستی درباره تعداد عاملها برسیم.
در این روش برای انتخاب تعداد عاملها، درصدهای تجمعی واریانس به دست آمده توسط عاملها ملاک عمل قرار میگیرد. یعنی تنها عاملهایی را میپذیریم که میزان کافی از واریانس متغیرها را تبیین کنند. این مقدار در رشتههای علوم پزشکی و رشتههای مشابه ۸۰ تا ۹۰ درصد و در رشتههای علوم اجتماعی و انسانی معمولاً ۶۰ درصد است.
بر اساس آزمون کایزر، تنها عاملهایی را انتخاب و حفظ میکنیم که مقدار ویژه آنها بالاتر از ۱ باشد.
ﻧﻤﺎﻳﺶ ﺗﺼﻮﻳﺮﻱ ﻭ ﮔﺮﺍﻓﻴﻜﻲ، مقادیر ﻭﻳﮋﻩ ﻫﺮ ﻳﻚ ﺍﺯ متغیرها توسط ﻧﻤﻮﺩﺍﺭ ﺍﺳﻜﺮﻱ (Scree) ﻧﺸﺎﻥ ﺩﺍﺩﻩ ﻣﻲﺷﻮﺩ. ﺁﺯﻣﻮﻥ ﺍﺳﻜﺮﻱ ﺑﺮﺍﻱ ﺍﻭﻟﻴﻦ ﺑﺎﺭ ﺗﻮﺳﻂ ﺁﺭ .ﺑﻲ. ﻛﺘﻞ (۱۹۹۶) ﻣﻄﺮﺡ ﺷﺪﻩ که ﺳﺎﻝﻫﺎ ﺑﻌﺪ ﺑﻪ ﻧﺎﻡ ﻧﻤﻮﺩﺍﺭ ﺍﺳﻜﺮﻱ ﻣﻮﺭﺩ ﺍﺳـﺘﻔﺎﺩﻩ ﻗـﺮﺍﺭ ﮔﺮﻓﺘـﻪ ﺍﺳـﺖ. ﺩﺭ ﺍﻳـﻦ نمودار بر ﺭﻭﻱ ﻣﺤﻮﺭ ﺍﻓﻘﻲ (xﻫﺎ) ﻋﺎﻣﻞﻫﺎ ﻭ ﺭﻭﻱ ﻣﺤﻮﺭ ﻋﻤﻮﺩﻱ (yﻫﺎ) ﻣﻘﺪﺍﺭ ﻭﻳﮋﻩ متناظر با هر عامل ﻗﺮﺍﺭ ﻣﻲﮔﻴﺮﺩ. ﺍﺯ ﻃﺮﻳــﻖ ﻧﻤــﻮﺩﺍﺭ ﺍﺳــﻜﺮﻱ ﻣــﻲﺗــﻮﺍﻥ ﺗﻌــﺪﺍﺩ ﻋﺎﻣــﻞﻫــﺎﻱ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺭﺍ ﺑﺮﺁﻭﺭﺩ ﻧﻤﻮﺩ. نموﺩﺍﺭ ﺍﺳﻜﺮﻱ ﺑﻪ ﺩﻭ ﺻﻮﺭﺕ ﺗﻔـﺴﻴﺮ ﻣـﻲﺷـﻮﺩ.
ﻳﻜـﻲ ﺍﺯ ﻃﺮﻳـﻖ ﺭﻭﺵ ﺁﻣﺎﺭﻱ ﻛﻪ ﺑﺮ ﺍﺳﺎﺱ ﺁﻥ، ﻋﺎﻣﻞﻫﺎﻳﻲ ﻛﻪ مقدار ﻭﻳـﮋﻩ ﺑـﺎﻻﺗﺮ ﺍﺯ ﻳﻚ ﺩﺍﺭﻧﺪ ﺑﻪ ﻋﻨﻮﺍﻥ ﻋﺎﻣﻞ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺍﻧﺘﺨﺎﺏ ﻣﻲﺷﻮﻧﺪ ﻭ ﺩﻳﮕﺮی ﺭﻭﺵ ﭼﺸﻤﻲ ﺍﺳﺖ ﻛﻪ ﺑﺮ ﺍﺳﺎﺱ ﺁﻥ بر ﺭﻭﻱ ﻋﺎﻣﻠﻲ ﻛﻪ ﺑﺎﻻﺗﺮﻳﻦ مقدار ﻭﻳﮋﻩ ﺭﺍ ﺩﺍﺭﺩ، یک ﺧﻂکش ﻗﺮﺍﺭ ﻣﻲدهیم ﺗﺎ ﺑﺮ ﻋﺎﻣﻞﻫـﺎﻳﻲ ﻛـﻪ ستارههای ﺁﻥ ﻣـﻮﺍﺯﻱ با ﻣﺤـﻮﺭ X ﻧـﺸﺪﻩﺍﻧـﺪ ﺑـﻪ ﺻـﻮﺭﺕ ﺯﺍﻭﻳـﻪ ﻣﻲﭼﺮﺧﺪ، ﺑﻪ ﺍﻳﻦ ﺻﻮﺭﺕ ﺁﻥ ﻋﺎﻣﻞﻫﺎﻳﻲ ﻛﻪ ﺭﻭﻱ ﺁﻥ ﺧﻂﻛـﺶ ﻳـﺎ ﺩﺭ ﺯﺍﻭﻳﻪﻫﺎﻱ ﺣﺮﻛﺖ ﺩﺍﺩﻩ ﺷﺪﻩ ﺁﻥ ﺧﻂﻛﺶ ﻗﺮﺍﺭ ﻣـﻲﮔﻴﺮﻧـﺪ ﺑـﻪ ﻃﻮﺭ ﺗﻘﺮﻳﺒﻲ ﺑﻪ ﻋﻨﻮﺍﻥ ﻋﻮﺍﻣﻞ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺍﻧﺘﺨﺎﺏ ﻣﻲﺷﻮﻧﺪ. چیزی که در این نمودار اهمیت دارد تغییر جهت در شکل نمودار است. با توجه به نمودار Scree ، تنها عاملهای بالای نقطه تغییر حفظ یا نگه داشته میشوند.
اشکال این آزمون این است که تفسیر آن ذهنیتر است و افراد مختلف ممکن است نتایج متفاوتی از ان نمودار استنباط کنند.
در این روش مقادیر ویژه مشاهده شده در دادهها با مقادیر ویژهای که از دادههای تصادفی انتظار میرود، مقایسه میشوند. یکی از راههای اجرای تحلیل موازی یک روش کامپیوتری به نام MonteCarloPCA است که به منظور تصادفی کردن نمرات هر متغیر در فایل دادههای شما به کار میرود. تا زمانیکه مقدار ویژه به دست آمده از SPSS بزرگتر از مقدار ویژه متناطر در نمرات تصادفی باشد، ان عامل حفظ میشود.
برای اینکه ﺭﺍﺑﻄﻪ ﺑﻴﻦ ﺁﻳﺘﻢﻫﺎ ﻭ ﻋﺎﻣـﻞﻫـﺎ به حداکثر برسد، ﺑﺎﻳـﺪ ﻣﺤﻮﺭﻫﺎ ﭼﺮﺧﺎﻧﺪﻩ ﺷﻮﻧﺪ. ﺍﺯ ﻃﺮﻳﻖ ﭼﺮﺧﺶ ﻋﺎﻣﻞﻫﺎ ﺑﻬﺘﺮﻳﻦ ﺗﺮﻛﻴـﺐ آیتمها ﻭ ﺳﺎﺧﺘﺎﺭ ﻋﺎﻣﻠﻲ ﺍﻳﺠﺎﺩ ﻣﻲﺷﻮﺩ. ﻋﻤﺪﻩﺗﺮﻳﻦ ﻫﺪﻑ ﺩﺭ ﭼﺮﺧﺶ ﻋﺎﻣﻞﻫـﺎ، تحول ساختار عاملی به یک ساختار ساده از بار عاملی است ﻛﻪ ﺑـﻪ ﺳـﺎﺩﮔﻲ بتوﺍﻥ ﻣﻮﺭﺩ ﺗﻔﺴﻴﺮ ﻗﺮﺍﺭ ﺩﺍﺩ. ﺗﻔﺴﻴﺮ ﻋﺎﻣﻞﻫﺎﻱ ﻣﺎﺗﺮﻳﺲ ﭼـﺮﺧﺶ ﻳﺎﻓﺘـﻪ بسیار ﺳﺎﺩﻩﺗﺮ ﺍﺯ ﺗﻔﺴﻴﺮ ﻋﺎﻣﻞﻫﺎﻱ ﻣﺎﺗﺮﻳﺲ ﭼﺮﺧﺶ ﻧﻴﺎﻓﺘﻪ ﻣﻲﺑﺎﺷﺪ.
۱- چرخش متعامد (ناهمبسته): چرخش متعامد منجر به راهحلهایی میشود که تفسیر و گزارش آنها ساده و راحت است. ولی در این روش فرض بر این است که سازههای زیربنایی مستقلند (همبستگی ندارند). به عبارت دیگر عاملها طوری چرخانده میشوند که با یکدیگر زاویه ۹۰ درجه داشته باشند.
۲- متمایل (ناهمبسته): روشهای متمایل به عاملها این امکان را میدهند که همبسته باشند، ولی تفسیر آن دشوارتر است.
در نرم افزار SPSS، چهار روش چرخش متعامد شامل واریماکس (Varimax)، کواریتمکس(Quartimax)، اکومکس (Equamax)و دو روش متمایل شامل ابلیمن مستقیم (Oblimin Direct) و پرومکس(Promax) وجود دارد.
از بین ﻣﺠﻤﻮﻋـﻪ ﺭﻭﺵﻫـﺎ ﻱ ﭼـﺮﺧﺶ ﻣﻌﺮﻭﻑﺗﺮﻳﻦ ﻭ ﭘﺮﻛﺎﺭﺑﺮﺩﺗﺮﻳﻦ ﺭﻭﺵ، ﭼﺮﺧﺶ ﻭﺍﺭﻳﻤﺎﻛﺲ ﻣـﻲﺑﺎﺷـﺪ. ﺩﺭ ﭼﺮﺧﺶ ﻭﺍﺭﻳﻤﺎﻛﺲ ﺍﺳﺘﻘﻼﻝ ﺑﻴﻦ ﻋﺎﻣﻞﻫﺎﻱ ﺭﻳﺎﺿﻲ ﺣﻔﻆ ﻣﻲﺷﻮﺩ. ﺍﻳﻦ ﻣﻮﺿﻮﻉ ﺍﺯ ﻧﻈﺮ ﻣﻬﻨﺪﺳﻲ ﺑﻪ ﺍﻳﻦ ﻣﻌﻨـﻲ ﺍﺳـﺖ ﻛـﻪ ﺩﺭ ﻣﻮﻗﻊ ﭼﺮﺧﺶ، ﻣﺤﻮﺭﻫﺎ ﻣﺘﻌﺎﻣﺪ ﺑﺎﻗﻲ ﻣﻲﻣﺎﻧﻨﺪ. ﺑﻪ ﻋﺒـﺎﺭﺕ ﺩﻳﮕـﺮ ﺍﺯ ﻃﺮﻳﻖ ﺣﻔـﻆ ﺯﻭﺍﻳـﺎﻱ ﻗﺎﺋﻤـﻪ ﻋﺎﻣـﻞﻫـﺎ ﻋﻤـﻮﺩ ﺑـﺮ ﻫـﻢ ﻣـﻲﻣﺎﻧﻨـﺪ. ﺍﺯ ﻃﺮﻳﻖ ﭼﺮﺧﺶ ﻭﺍﺭﻳﻤـﺎﻛﺲ ﻋﺎﻣـﻞﻫـﺎ ﺑـﻪ ﻣﺤﻮﺭﻫﺎﻱ ﺟﺪﻳﺪ ﺍﻧﺘﻘﺎﻝ ﺩﺍﺩﻩ ﻣﻲﺷـﻮﻧﺪ ﺗـﺎ ﺍﺯ ﺁﻥ ﻃﺮﻳـﻖ ﻣﺠﻤﻮﻋـﻪ آیتمهای ﺁﺯﻣﻮﻥ ﺑﺎ ﺳﺎﺧﺘﺎﺭ ﺳﺎﺩﻩﺍی ﻛﻪ ﻧﻤﺎﻳﺸﮕﺮ ﺧﻄـﻮﻁ ﺍﺻـﻠﻲ ﻭ ﻧﺴﺒﺘﺎ ﻭﺍﺿﺢ، ﺟﻬﺖ ﺭﺳﻴﺪﻥ ﺑﻪ ﺭﺍﻩ ﺣﻞﻫﺎﻱ ﺗﻔﺴﻴﺮ ﭘﺬﻳﺮ ﺑﺎﺷﺪ، ﺍﻣﻜـﺎﻥ ﭘﺬﻳﺮ ﮔﺮﺩﺩ. ﺑﺎ ﻭﺟـﻮﺩ ﺍﻳـﻦﻛـﻪ ﺳـﺎﻳﺮ ﺭﻭﺵﻫـﺎﻱ ﭼـﺮﺧﺶ ﺗﻔﺴﻴﺮﻫﺎﻱ ﻣﺘﻔﺎﻭﺗﻲ ﺩﺍﺭﻧﺪ، ﺍﻣﺎ ﻫﻤﻪ ﺁﻥﻫﺎ ﺻﺮﻓﺎ ﺑﺎ ﻫﺪﻑ ﺑﻪ ﺣـﺪﺍﻛﺜﺮ ﺭﺳﺎﻧﺪﻥ ﺭﺍﺑﻄـﻪ ﺑـﻴﻦ ﻣﺘﻐﻴﺮﻫـﺎ ﻭ ﺑﺮﺧـﻲ ﺍﺯ ﻋﺎﻣـﻞﻫـﺎ ﺑـﻪ ﻛـﺎﺭ ﮔﺮﻓﺘـﻪ ﻣﻲﺷﻮﻧﺪ.
ﻳﻜﻲ ﺍﺯ ﻣﺸﻜﻞﺗﺮﻳﻦ ﻭ ﺩﺭ ﻋﻴﻦ ﺣﺎﻝ ﻣﻬﻢﺗﺮﻳﻦ ﻣﺮﺍﺣـﻞ ﺗﺤﻠﻴـﻞ ﻋﻮﺍﻣﻞ، ﻧﺎﻡﮔﺬﺍﺭﻱ ﻋﺎﻣﻞﻫﺎﻱ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺍﺳﺖ. ﻧﺎﻡ ﮔـﺬﺍﺭﻱ ﻋﻮﺍﻣـﻞ ﺍﺳﺘﺨﺮﺍﺟﻲ ﺗﺤﺖ ﺗﺎﺛﻴﺮ ﺩﻭ ﻋﺎﻣﻞ ﺑﺮﺭﺳﻲ ﻓﻨﻲ آیتمﻫﺎﻱ ﻳﻚ ﻋﺎﻣﻞ ﻭ ﺍﺻﻮﻝ ﺭﻭﺍﻧﺸﻨﺎﺧﺘﻲ ﺣﺎﻛﻢ ﺑﺮ آیتمهای ﻋﺎﻣﻞ ﻣﻲﺑﺎﺷﺪ. ﺍﮔﺮ ﭼﻪ بارهای ﻋﺎﻣﻠﻲ ﻫﺮ ﻋﺎﻣﻞ ﻧﻤﺎﻳﺶ ﺩﻫﻨﺪﻩ ﻳﻚ ﺻﻔﺖ ﺍﺷﺘﺮﺍﻛﻲ است ﻛﻪ عامل موردنظر ﺁﻥ ﺭﺍ ﺍﻧﺪﺍﺯﻩﮔﻴﺮﻱ میکند، ﺍﻣﺎ ﺑﺎﻳﺪ ﺗﻮﺟﻪ ﺩﺍﺷﺖ ﻛﻪ ﺻـﺮﻓﺎ با استفاده از بار ﻋـﺎﻣﻠﻲ ﻧﻤـﻲﺗﻮﺍن ﺑـﻪ ﻧـﺎﻡﮔﺬﺍﺭﻱ ﺻﻔﺖ ﻣﻜﻨـﻮﻧﻲ ﻛـﻪ ﻋﺎﻣـﻞ ﻗـﺼﺪ ﺍﻧـﺪﺍﺯﻩﮔﻴـﺮﻱ ﺁﻥ ﺭﺍ ﺩﺍﺭد، پرداخت. بنابراین بار ﻋــﺎﻣﻠﻲ ﺑــﺮﺍﻱ ﻧﺎﻡﮔﺬﺍﺭﻱ ﻋﺎﻣﻞ، ﺷﺮﻁ ﻻﺯﻡ ﺍﺳﺖ ﺍﻣﺎ ﺷﺮﻁ ﻛﺎﻓﻲ ﻧﻴﺴﺖ.
ﺑﺮﺍﻱ ﻣﺜﺎﻝ ﺍﮔﺮ ﺭﻭﻱ ﻳﻚ ﻋﺎﻣﻞ، ٧ آیتم ﻗﺮﺍﺭ ﮔﺮﻓﺘﻪ ﺑﺎﺷﺪ ﻭ ٧ آیتم ﻧﻴﺰ ﺩﺍﺭﺍﻱ بار ﻋﺎﻣﻠﻲ ﺑﺎﻻﺗﺮ ﺍﺯ ۰٫۴۰ ﺑﺎﺷﺪ ﻭ ﻫﻤﻪ ﺁﻥﻫﺎ ﺑﻪ ﻧﻮﻋﻲ ﻭﻳﮋﮔﻲﻫﺎﻳﻲ ﻣﺎﻧﻨﺪ ﺷﻮﺥ ﻃﺒﻌﻲ، ﺣﻀﻮﺭ ﻳﺎ ﻋﺪﻡ ﺣﻀﻮﺭ ﺩﺭ ﻣﺴﺎﺋﻞ ﺍﺟﺘﻤﺎﻋﻲ، ﺍﻧﻌﻄﺎﻑ ﭘﺬﻳﺮﻱ ﺩﺭ ﻣﻘﺎﺑﻞ ﺑﺪﻭﻥ ﺍﻧﻌﻄﺎﻑ، ﺑﻪ ﺧﻮﺩ ﺗﻮﺟﻪ ﻛﺮﺩﻥ ﺩﺭ مقابل ﺑﻪ ﺩﻳﮕﺮﺍﻥ ﺗﻮﺟﻪ ﻧﻤﻮﺩﻥ، ﺍﻫﻞ ﻣﻌﺎﺷﺮﺕ ﺑﻮﺩﻥ ﻭ ﻧﺒﻮﺩﻥ ﻭ ﻣﺸﺎﺑﻪ ﺁﻥ ﺑﺎﺷﻨﺪ، ﻣﻲ ﺗﻮﺍﻥ ﻋﺎﻣﻞ ﺭﺍ ﺑﺎ ﻋﻨﻮﺍﻥ ﺩﺭﻭﻥﮔﺮﺍﻳﻲ ﺩﺭ ﻣﻘﺎﺑﻞ ﺑﺮﻭﻥﮔﺮﺍﻳﻲ ﻧﺎﻡﮔﺬﺍﺭﻱ ﻧﻤﻮﺩ.
ﺩﺭ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺗﺎﺋﻴـﺪﻱ ﻣﺪﻝﻫﺎﻱ ﻣﺘﻔﺎﻭﺗﻲ ﻣﻮﺭﺩ ﻣﻘﺎﻳﺴﻪ قرﺍﺭ ﻣﻲﮔﻴﺮﻧﺪ ﺗـﺎ ﻣـﺸﺨﺺ ﺷـﻮﺩ ﻛﺪﺍﻡ ﻣﺪﻝ ﺑﻬﺘﺮﻳﻦ ﺑﺮﺁﻭﺭﺩ ﺭﺍ ﺍﺯ ﺩﺍﺩﻩﻫﺎ ﻧﺸﺎﻥ ﻣـﻲﺩﻫـﺪ. ﺩﺭ ﺗﺤﻠﻴـﻞ ﻋﺎﻣﻠﻲ ﺗﺎﺋﻴﺪﻱ ﺑﺮ ﺧﻼﻑ ﺗﺤﻠﻴﻞ ﻋﺎﻣﻠﻲ ﺍﻛﺘﺸﺎﻓﻲ، ﻛـﺎﺭﺑﺮ ﺍﺯ ﻗﺒـﻞ ﺩﺭ ﻣﻮﺭﺩ ﻭﺟﻮﺩ ﺗﻌﺪﺍﺩ ﺧﺎﺻﻲ ﺍﺯ ﻋﻮﺍﻣﻞ ﺗﺼﻤﻴﻢ ﮔﻴﺮﻱ ﻣﻲﻛﻨﺪ، ﺑﻪ ﻃﻮﺭﻱ ﻛﻪ ﻣﻤﻜﻦ ﺍﺳـﺖ ﺍﺯ ﻗﺒـﻞ ﺩﺭ ﻣـﻮﺭﺩ ﻭﺟـﻮﺩ ﻳـﺎ ﻋـﺪﻡ ﻭﺟـﻮﺩ ﻧﻘـﺶ ﺁﺯﻣﻮﻥﻫﺎﻱ ﻣﻮﺭﺩ ﻧﻈﺮ ﺭﻭﻱ ﻋﺎﻣﻞﻫﺎ، ﻓﺮﺽﻫﺎﻳﻲ ﺭﺍ ﻧﻴﺰ ﺑﻴﺎﻥ ﻛﻨﺪ.
تمایز مهم روشهای تحلیل اکتشافی و تأییدی در این است که روش اکتشافی با صرفهترین روش تبیین واریانس مشترک زیربنایی یک ماتریس همبستگی را مشخص میکند. در تحلیل عاملی تأییدی محقق مطالعه خود را بر مبنای ساختار عاملی از پیش تعیین شده دنبال میکند و درصدد است تا صحت و سقم ساختار عاملی مجموعهای از متغیرهای مشاهده شده را مورد آزمون قرار دهد. این تکنیک به محقق اجازه میدهد تا به آزمون این فرضیه که بین متغیرهای آشکار و سازههای پنهان رابطه وجود دارد را مورد بررسی قرار دهد.
تحلیل عاملی تأییدی در واقع یک مدل آزمون تئوری است که در آن پژوهشگر تحلیل خود را با یک فرضیه قبلی آغاز میکند. این مدل مشخص میکند که کدام متغیرها با کدام عاملها و کدام عامل با کدام عاملها باید همبسته شوند. روش تأییدی بعد از مشخص کردن عاملهای پیش تجربی، از طریق تعیین برازندگی مدل عاملی از پیش تعیین شده، تطابق بهینه ساختارهای عاملی مشاهده شده و نظری را برای مجموعه دادهها آزمون میکند. از اینرو، تحلیل عاملی تأییدی، مورد ویژهای از مدلیابی معادلات ساختاری است.
توجه: در تحلیل عاملی، محقق همواره فرض میکند که متغیرهای پنهان علت متغیرهای آشکار هستند. به همین دلیل فلشها از متغیرهای پنهان منشأ گرفته و به متغیرهای آشکار ختم میشوند.
تدوین مدل براساس تئوری صورت میگیرد. در تدوین مدل، تعداد عاملهای مدل، تعداد شاخصها، الگوی روابط بین شاخصها و عاملها و محدودیتهای مدل (مشخصکردن پارامترهای ثابت، آزاد و مقید مناسب) مشخص میشود. در این مرحله فرض میشود که بین هیچیک از خطاها همبستگی وجود ندارد.
تشخیص مدل یعنی آیا برای هریک از پارامترهای آزاد، میتوان یک مقدار منحصر به فرد از روی دادهها به دست آورد. براساس این تعریف سه نوع مدل خواهیم داشت:
مدلهای فرومشخص (under-identified): یک برآورد واحد برای هر پارامتر ناممکن باشد. یا به عبارتی اطلاعات مورد نیاز برای حل کردن پارامترها ناکافی باشد.
مدلهای کاملاً مشخص (just-identified): برای هر پارامتر واحد میتوان یک مقدار واحد برآورد کرد. یا به عبارتی تعداد معادلات با تعداد پارامترهای مورد تخمین برابر است.
مدلهای فرامشخص (over-identified): مدلهایی که برای هر پارامتر بیش از یک جواب دارند. یعنی تعداد پارامترهای مدل کمتر از مشاهدات است.
تعداد پارامترهایی که باید برآورد شوند (پارامترهای آزاد) نباید از تعداد واریانسها و کوواریانسهای نمونه بیشتر باشد. اگر تعداد متغیرهای مشاهده شده (شاخصها) برابر P باشد بنابراین از طریق فرمول زیر میتوان تعداد کل واریانسها و کوواریانسهای ممکن را برآورد نمود.
p × (p+1)〉 / ۲〉= تعداد کل واریانسها و کوواریانسهای نمونه
برآورد مدل شامل تکنیکهایی است که برای برآورد پارامترهای مدل استفاده میشوند. برآورد پارامترها آنقدر تکرار میشود تا مدل موردنظر در یک مجموعه نهایی از پارامترهای برآورد شده همگرا شود.
یک بخش مهم در فرایند برآورد، ارزیابی برازش مدل است. منظور از برازش مدل این است که تا چه حد یک مدل با دادههای نمونه سازگاری و توافق دارد. بدین منظور از شاخصهای برازش استفاده میشود.
در صورتی که برازش مدل قابل قبول باشد، تخمین پارامترها مورد بررسی قرار میگیرند. یعنی نتایج بخش اندازهگیری و ساختاری مدل ارزیابی میشوند. نسبت تخمین هر پارامتر به خطای استاندارد آن بوسیله آماره t نشان داده میشود. برای اینکه پارامتر موردنظر قابل قبول یا به عبارتی معنادار باشد، باید قدرمطلق مقدار t آن بزرگتر یا مساوی ۱٫۹۶ باشد. بنابراین شاخصها از دقت لازم برای اندازه گیری سازههای نهفته تحقیق برخوردارند.
گرچه انواع گوناگونی از آزمونها که به آنها شاخصهای برازش گفته میشود، در حال توسعه و تکامل میباشند. اما هنوز درباره حتی یک آزمون بهینه نیز توافق همگانی وجود ندارد. تصمیمگیری درباره برازش یک مدل براساس چند شاخص و نه یک شاخص انجام میگیرد. بنابراین برای ارزیابی برازش مدل، ضروری است تعداد متنوعی از شاخصها گزارش شود. زیرا شاخص های مختلف، جنبههای متفاوتی از برازش مدل را انعکاس میدهند. برخی از این شاخصها عبارتند از:
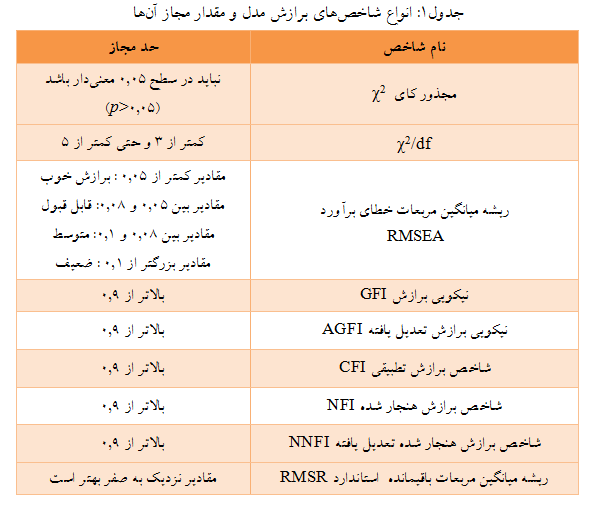
شاخصهای دیگری نیز در خروجی نرم افزار لیزرل دیده میشوند که برخی مثل AIC ،CAIC و ECVI برای تعیین برازندهترین مدل از میان چند مدل مورد توجه قرار میگیرند برای مثال مدلی که دارای کوچکترینAIC ،CAIC و ECVI باشد برازندهتر است. مقدار آماره ECVI به خودی خود قابل قضاوت نیست و برای نتیجهگیری درباره برازش مدل با مقادیر بدست آمده برای مدل استقلال و مدل اشباع شده مقایسه میگردد. مدلی که دارای کوچکترین CAIC و AIC باشد (هرچه به صفر نزدیکتر باشند)، برازندهتر است. برخی از شاخصها نیز به شدت وابسته به حجم نمونهاند و در حجم نمونههای بالا میتوانند معنا داشته باشند.
گام نهایی اصلاح مدل نامیده میشود. در صورتی که مدل از برازش ضعیفی برخوردار باشد، با استفاده از اطلاعات حاصل از خروجی برنامه، جهت بهبود مدل تغییراتی در آن اعمال میشود.
بار عاملی، معرف همبستگی متغیر آشکار با عامل است، در نتیجه مانند هرگونه همبستگی دیگر تفسیر میشود. بعلاوه وجود بارهای منفی نشان میدهد برخی از متغیرها بیانگر عکس چیزی هستند که بوسیله آن عامل مشخص میشود. همچنین، اهمیت نسبی متغیرها بوسیله مقدار مجذور بارهای عاملی نشان داده میشود. هرچه بار یک متغیر در یک عامل بزرگتر باشد، وزن بیشتری به آن متغیر میدهد.
بارهای استاندارد شده از اهمیت زیادی در تفسیر نتایج تحلیل عاملی برخوردارند و امکان مقایسه پارامترهای مدل با یکدیگر را فراهم میکنند.
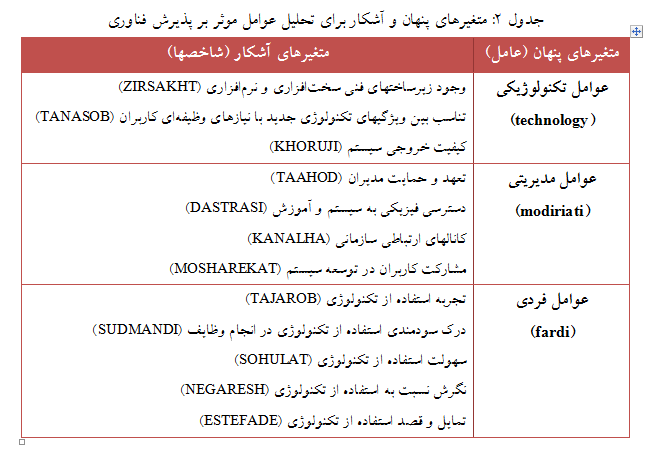
محققی قصد دارد به منظور بررسی عوامل موثر بر پذیرش فناوری در آموزشهای مجازی کارکنان یک سازمان، نظر ۴۰۰ نفر از کارکنان آموزش دیده آن را جویا شود. وی با استفاده از یک پرسشنامه از کارکنان خواسته است تا عوامل مطرح شده را در طیف ۵ نقطهای لیکرت رتبهبندی کنند. این محقق براساس یک مدل نظری، ۱۲ متغیر آشکار (یا شاخص) را در قالب سه متغیر پنهان (یا عامل) شامل عوامل تکنولوژیکی، عوامل مدیریتی و عوامل فردی مدنظر قرار داده است. این عوامل و شاخصهای آنها در جدول زیر ارائه شدهاند.
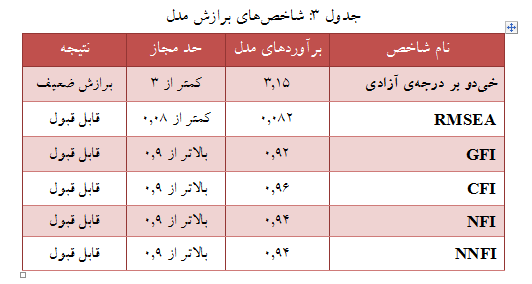
پس از انجام فرایند تحلیل عاملی با استفاده از نرمافزار لیزرل ابتدا با توجه به خروجی آن باید به تعیین برازش مدل پرداخت. اگر میزان برازش قابل قبول بود، آنگاه به بررسی نتایج و تحلیل بارهای عاملی میپردازیم. نتایج چند شاخص برازندگی مدل در جدول زیر ارائه میشود:
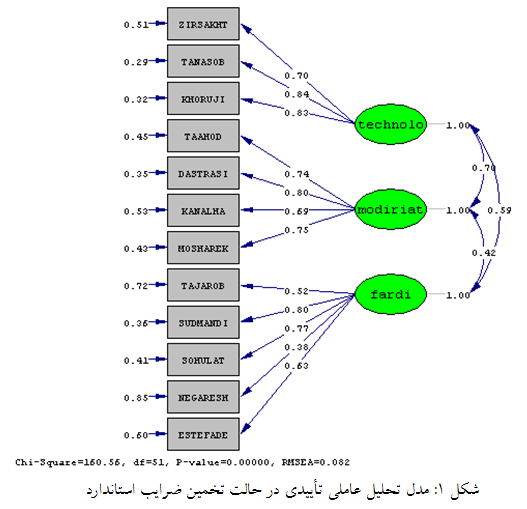
با توجه به شکل ۱، همه متغیرها متغیرها همبستگی بالایی را با سازه مربوط به خود نشان میدهند. فقط متغیر نگرش (۰٫۳۸) در مقایسه با سایر متغیرها از همبستگی پایینتری با عوامل فردی برخوردار است.
متغیر “تناسب” دارای بار عاملی ۰٫۸۴ است که نشان میدهد ۷۱ درصد واریانس مشترک برآورد شده (۰٫۷۱ = ۲(۰٫۸۴)) در این متغیر از سوی عامل تکنولوژی تعیین میشود.
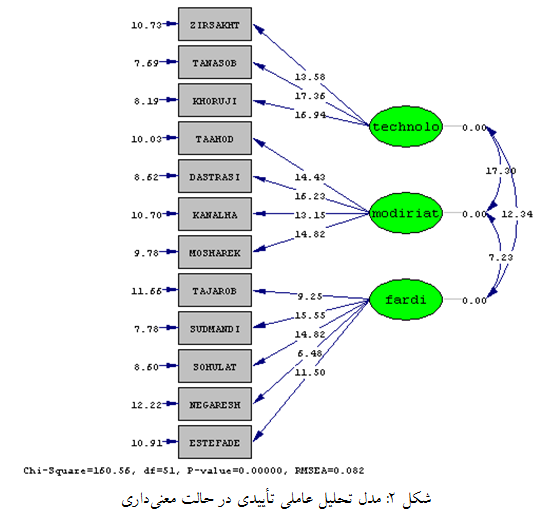
بررسی معنیداری آنها با توجه به خروجی نرمافزار نشان میدهد که بارهای عاملی بدست آمده در خصوص تمام متغیرهای آشکار در سطح ۰٫۰۵ معنیدار هستند و همانگونه که در دیاگرام شکل ۲ نشان داده شده، مقدار t همه بارهای عاملی از ۱٫۹۶ بزرگتر هستند.
تحلیل عاملی مرتبه دوم یا تحلیل عاملی مرتبه بالاتر توسعه یافته تحلیل عاملی است. این روش بر اساس مدلهای سلسله مراتبی است که اغلب در علوم انسانی و علوم طبیعی با جدیت بیشتری دنبال میشود. در تحلیل عاملی مرتبه دوم، فرض بر آن است که خود متغیرهای پنهان در واریانس مشترک ناشی از یک یا چند عامل مرتبه بالاتر سهیم هستند. به عبارت دیگر، عاملهای مرتبه دوم به واقع عاملهای عاملها به حساب میآیند. میتوان گفت که تحلیل عاملی مرتبه دوم روش بسیار مفیدی برای تحلیل دادهها است که قدرت تفسیر بالایی را در اختیار پژوهشگر قرار می دهد.
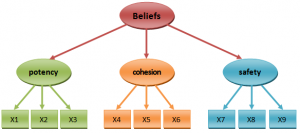
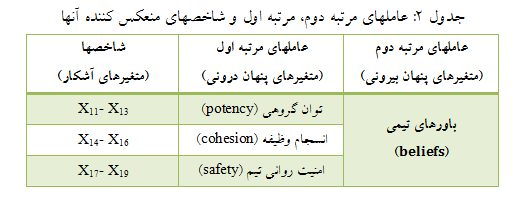
محققی به منظور تأیید روایی سازه و ساختار عاملی پرسشنامهای برای اندازهگیری باورهای تیمی مدل تحلیل عاملی مرتبه دوم اجرا شده است. برای باورهای تیمی در این مدل، ۳ مولفه شامل توان گروهی، انسجام وظیفه و امنیت روانی تیم و برای اندازهگیری هر یک از این مولفهها سه گویه درنظر گرفته شده که شرح آنها در جدول ۲ ارائه شده است. محقق برای بررسی اینکه آیا ابعاد و شاخصهای انتخابی وی برای اندازهگیری باورهای تیمی مناسب بوده و در قالب یک مفهوم (یعنی باورهای تیمی) قرار میگیرند، از تحلیل عاملی مرتبه دوم استفاده نموده است.
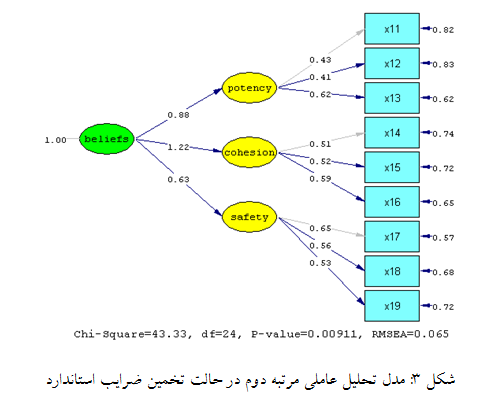
شکل ۳ بارهای عاملی مرتبه اول و دوم برای سازه باورهای تیمی را در حالت تخمین ضرایب استاندارد نشان میدهد.
به عنوان مثال، در بین بارهای عاملی مرتبه دوم، “انسجام وظیفه” (cohesion) بیشترین بار عاملی (۱٫۲۲) و “امنیت روانی” (safety) کمترین بار عاملی (۰٫۶۳) روی سازه “باورهای تیمی” (beliefs) را دارا میباشند.
در بین بارهای عاملی مرتبه اول از بین گویههای مربوط به مولفه “انسجام وظیفه” (cohesion)، گویه X16 از بیشترین بار عاملی (۰٫۵۹) و X14 از کمترین بار عاملی (۰٫۵۱) برخوردار است.
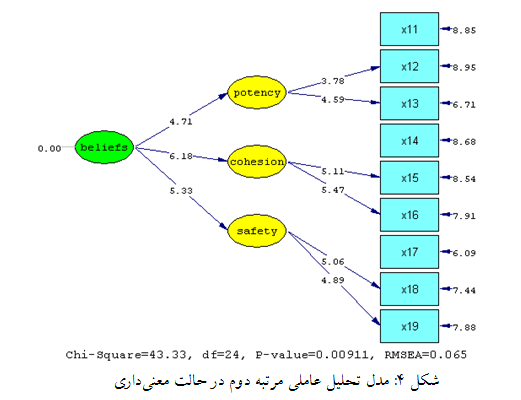
شکل ۴ مدل تحلیل عاملی تأییدی مرتبه دوم را در حالت معناداری (مقادیر t-value) نشان میدهد. این مدل در واقع تمامی معادلات اندازهگیری مرتبه اول و دوم (بارهای عاملی) را با استفاده از آماره t، آزمون میکند (یادآوری میشود که اگر مقدار قدرمطلق آمارهی t بزرگتر از ۱٫۹۶ باشد، معنیدار است). بر طبق این مدل (شکل ۴)، مقادیر محاسبه شده t برای تمامی بارهای عاملی مرتبه اول و مرتبه دوم از ۱٫۹۶ بزرگتر هستند و در نتیجه در سطح اطمینان ۹۵% معنادار میباشند. بنابراین، میتوان همسویی سؤالات پرسشنامه برای اندازهگیری مفاهیم را در این مرحله معتبر نشان داد. در واقع نتایج نشان میدهد آنچه محقق توسط سؤالات پرسشنامه قصد سنجش آنها را داشته است، توسط این ابزار محقق شده است.
برای آنکه نشان دهیم این مقادیر به دست آمده تا چه حد با واقعیتهای موجود در مدل تطابق دارد باید شاخصهای برازش مورد مطالعه قرار گیرد که نتایج آن در جدول زیر ارائه شده است:
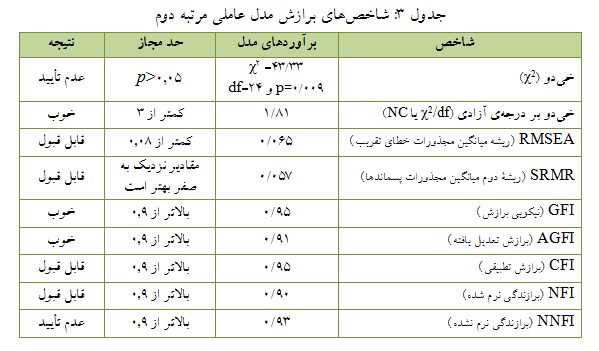
همانطور که شاخصهای برازندگی جدول ۳ نشان میدهد، دادههای این پژوهش با ساختار عاملی و زیربنای نظری تحقیق برازش مناسبی دارد.
با سلام
مطالبتون برای من مفید بود. تشکر میکنم از به اشتراک گذاری داشته هایتان!
سپاس
صالحی
فائزه حجتی
خواهش می کنم. موفق باشید
با سلام،
بسیار مفید و قابل استفاده بود.
سپاسگزارم
فائزه حجتی
متشکرم
مطالب اموزنده می باشد تشکر.
فائزه حجتی
متشکرم
عرض سلام و خسته نباشید...
مطالب بسیار بسیار با ارزش و کاربردی هستند
سوال اینکه آیا کانال تلگرام tahlil95_com فعالیت دارد؟
با تشکر
فائزه حجتی
متشکرم. نه کانالی نداریم
با سلام ممنون از مطالب خوبتون
آیا در تحلیل عاملی تاییدی، اماره تی به تنهایی کفایت می کند که برازش مدل را نشان دهد یا حتما باید بار عاملی هم نشان دهیم؟
فائزه حجتی
خواهش می کنم باید بارهای عاملی و شاخصهای برازش مدل نیز بررسی شود
سلام ممنونم. کامل و جامع بود. دقیقا همان مطالبی که نیاز داشتم.سپاس از شما