فائزه حجتی | بهمن ۲۵, ۱۳۹۵ | 5 دیدگاه
مدل یابی معادله ساختاری یک تکنیک تحلیل چند متغیری بسیار کلی و نیرومند از خانواده رگرسیون چند متغیری و به بیان دقیقتر بسط “مدل خطی عمومی” (General linear model) است که به پژوهشگر امکان میدهد مجموعه ای از معادلات رگرسیون را به گونه هم زمان مورد آزمون قرار دهد. مدل یابی معادله ساختاری،روشهای تحلیل عاملی، همبستگی کانونی و رگرسیون چندمتغیری را با یکدیگر ترکیب می کند.
یکی از قویترین و مناسبترین روشهای تجزیه و تحلیل در تحقیقات علوم رفتاری و اجتماعی، تجزیه و تحلیل چند متغیره است. زیرا ماهیت این گونه موضوعات چند متغیره بوده و نمیتوان آنها را با شیوه دو متغیری (که هر بار یک متغیر مستقل با یک متغیر وابسته در نظر گرفته میشود) حل نمود. تجزیه و تحلیل چند متغیره به یک سری روشهای تجزیه و تحلیل اطلاق میشود که ویژگی اصلی آنها تجزیه و تحلیل همزمان k متغیر مستقل و n متغیر وابسته است. مدل یابی معادله ساختاری یک رویکرد جامع برای آزمون فرضیههایی درباره روابط متغیرهای آشکار (مشاهده شده) و پنهان (نهفته یا مکنون) است که گاه تحلیل ساختاری کوواریانس، مدل یابی علّی و گاه نیز لیزرل (LISREL) نامیده شده است؛ اما اصطلاح غالب در این روزها، مدلیابی معادله ساختاری یا به گونه خلاصه SEM است.
از طریق این روش میتوان قابل قبول بودن مدلهای نظری را در جامعههای خاص با استفاده از دادههای همبستگی، غیر آزمایشی و آزمایشی آزمود. این روش برآوردهایی از پارامترهای مدل (ضرایب مسیر و عبارات خطا) و همچنین چند شاخص برای نیکویی برازش فراهم میکند و با بهرهگیری از دادههای تجربی امکان آزمون مدلهای تدوین شده را به عنوان یک کل فراهم آورده و با شاخصهایی که در اختیار پژوهشگر قرار میدهد، وی را در اصلاح و بهبود مدل راهنمایی میکند.
مدل یابی معادله ساختاری را می توان برای آزمون انواع مختلفی از مدلها مانند مدلهای رگرسیون، تحلیل مسیر، مدلهای تحلیل عاملی تاییدی، مدلهای عاملی مرتبه دوم، مدلهای MIMIC (مدلهای با شاخصهای چندگانه و علل چندگانه)، مدلهای چندسطحی، مدلهای گروههای چندگانه و …. به کار برد.
سول رایت (Sewall Wright) تحلیل مسیر را به عنوان روشی برای مطالعۀ تأثیرات مستقیم و غیرمستقیم متغیرهایی که علت گرفته شدهاند در متغیرهایی که معلول فرض شدهاند ساخت و پرداخت. باید در نظر داشت که از تحلیل مسیر برای کشف علتها استفاده نمیشود بلکه این روش در مورد مدلهایی به کار میرود که بر مبنای دانش و ملاحظات نظری تدوین شده باشند. تحلیل مسیر ابزار تحلیلی مهمی برای آزمودن نظریه هاست که از کاربرد آن محقق می تواند توافق الگویی از همبستگی ها را که از مجموعه ای از مشاهدات حاصل شده است، با یک مدل معین معلوم کند.
مدل مسیر: مدل مسیر دیاگرامی است که متغیرهای مستقل، میانجی یا واسطهای و وابسته را به هم مرتبط میکند. پیکانهای یکطرفه نشان دهندۀ علّیت بین متغیرهای برونزا یا واسطهای و متغیرهای وابسته هستند. پیکانها عبارتهای خطا را هم به متغیرهای درونزا مخصوص خود مرتبط میکنند. پیکانهای دو طرفه نشان دهنده همبستگی بین جفتهای متغیرهای برونزا هستند.
ضرایب مسیر: ضریب مسیر یک ضریب رگرسیون استاندارد (بتا) است که اثر مستقیم یک متغیر مستقل روی یک متغیر وابسته را در مدل مسیر نشان میدهد. بنابراین زمانی که مدل دو یا چند متغیر علّی دارد، ضرایب مسیر ضرایب رگرسیون پارهای هستند که میزان تأثیر یک متغیر روی متغیر دیگر را با کنترل سایر متغیرها در مدل اندازه میگیرد. برآوردهای مسیر میتوانند توسط رگرسیون حداقل مجذورات یا بیشینه درست نمایی برآورد شوند.
اثرات مستقیم و غیرمستقیم: ضرایب مسیر میتوانند برای تجزیه همبستگی بین دو متغیر به اثرات مستقیم و غیرمستقیم استفاده شوند. اثرهای غیرمستقیم مستلزم متغیرهای میانجی است.
به طور کلی در مدل یابی معادله ساختاری (SEM) برای برآورد پارامترهای مدل دارای دو نوع میباشد که عبارتند از: رویکرد مبتنی بر کوواریانس و رویکرد مبتنی بر واریانس.
روش کوواریانس محور که به عنوان نسل اول مدل یابی معادلات ساختاری شناخته شده است، به شدت به حجم نمونه بالا بستگی دارد و هر چه دادهها نرمالتر باشند، برازش بهتری را نشان میدهد. روش کوواریانس محور تلاش میکند تا اختلاف بین کوواریانسهای نمونه و آنچه که مدل نظری پیشبینی کرده است را به حداقل برساند. نرم افزار LISREL یکی از ﻗﻮیترین و ﻣﻨﺎﺳﺐﺗﺮین رویکردهای کوواریانس محور برای تجزیه و تحلیل در ﺗﺠﺰیه و تحلیل ﭼﻨﺪ متغیره اﺳﺖ. زیرا ﻣﺎهیت این ﮔﻮﻧﻪ ﻣﻮﺿﻮﻋﺎت، دارای چند متغیر بوده و این متغیرها نیز با هم ارتباطات پیچیدهتری دارند و ﻧﻤﯽﺗﻮان آﻧﻬﺎ را ﺑﺎ شیوهای که ﺗﻨﻬﺎ ارتباط میان یک متغیر ﻣﺴﺘﻘﻞ ﺑﺎ یک متغیر واﺑﺴﺘﻪ بررسی میشود، ﺣﻞﻧﻤﻮد. روش کوواریانس محور برای توسعه نظریه مناسبتر است و با MPLUS ، AMOS وEQS نیز قابل اجرا میباشد.
متغیرهایی که با مشاهده مستقیم رویداد بدست میآیند که به عنوان شاخص اندازهگیری یک متغیر پنهان ایفای نقش میکنند و در دیاگرام مسیر با مستطیل مشخص میشوند.

متغیرهایی که مستقیماً قابل مشاهده نیستند. متغیرهای پنهان از طریق پیوند با متغیرهای قابل اندازهگیری (آشکار) بررسی و در دیاگرام مسیر با دایره یا بیضی مشخص میشوند. متغیرهای پنهان در مدل معادلات ساختاری به دو دسته بیرونی و درونی تقسیم میشوند.

متغیرهای پنهان بیرونی: متغیرهایی هستند که علت تغییرات آنها در مدل منظور نشده و تحت تأثیر متغیرهای دیگر مدل قرار ندارند.
متغیرهای پنهان درونی: متغیرهایی که تحت تأثیر یک یا چند متغیر دیگر قرار دارند.
خطاهای باقیمانده نشاندهنده خطای تصادفی متغیرهای آشکار و نیز متغیرهای پنهان هستند که درون خطوط بسته قرار نمیگیرند.
خطوط کشیده شده به سمت متغیرهای آشکار بیانگر خطاهای اندازهگیری هستند.
خطوط کشیده شده به سمت متغیرهای پنهان بیانگر واریانسهای باقیمانده یا از دست رفته هستند.

توجه: در مدل یابی معادله ساختاری، از خطوط راست (فلشهای یکطرفه) برای نشان دادن روابط علی یا تأثیر یک متغیر بر متغیر دیگر استفاده میشود.
![]()
خطوط منحنی (فلشهای دوطرفه) برای نشان دادن همبستگیها استفاده میشود.
مدل اندازهگیری روابط بین متغیرهای پنهان و آشکار (مولفههای یک متغیر پنهان) را تعریف میکند. مدل اندازهگیری دارای دو نوع میباشد:
مدل اندازهگیری X : روابط بین متغیر پنهان مستقل و متغیرهای آشکار مربوط به آن را نشان میدهد.
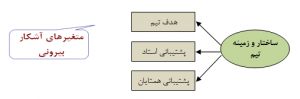
شکل ۱: مدل اندازهگیری X برای متغیر ساختار و زمینه تیم
مدل اندازهگیری Y : روابط بین متغیر پنهان وابسته و متغیرهای آشکار مربوط به آن را نشان میدهد.شکل ۱: مدل اندازهگیری X برای متغیر ساختار و زمینه تیم

شکل ۲: مدل اندازهگیری Y برای متغیر فراشناخت تیمی
مدل ساختاری، روابط بین متغیرهای پنهان را مشخص میکند.
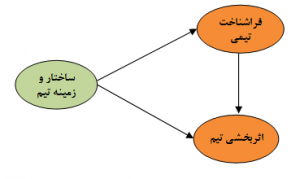 شکل ۳: مدل ساختاری
شکل ۳: مدل ساختاری
این مدل ترکیب دو مدل اندازهگیری و ساختاری است و در آن هم روابط بین متغیرهای پنهان با متغیرهای آشکار (مدل اندازهگیری) و هم روابط بین متغیرهای پنهان (مدل ساختاری) مورد توجه قرار میگیرد.
پژوهشی رابطه سه متغیر پنهان A، B وC به صورت زیر بررسی شده است:
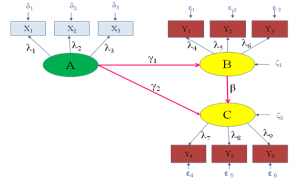
شکل ۴: نمونهای از یک مدل عمومی معادلات ساختاری براساس نمادها
تدوین مدل براساس تئوری صورت میگیرد. در تدوین مدل، تعداد متغیرهای پنهان مدل، تعداد متغیرهای آشکار، روابط بین متغیرهای پنهان و آشکار مربوطه، الگوی روابط بین متغیرهای پنهان و محدودیتهای مدل (مشخصکردن پارامترهای ثابت، آزاد و مقید مناسب) مشخص میشود.
تعداد متغیرها در تدوین مدل
تعداد متغیرها به موضوع مورد مطالعه، هدف تحقیق و امکان سنجش این متغیرها بستگی دارد. در مجموع هرچه مدل طراحی شده پیچیدهتر باشد، دستیابی به برازش مدل مشکلتر میشود. ضمن اینکه باید به خاطر داشت که هرچه تعداد متغیر در یک مدل بیشتر باشد باید حجم نمونه نیز افزایش یابد. هرچند قاعده قطعی برای تعیین تعداد متغیرهای مدل وجود ندارد، اما عدهای معتقدند که در یک مدل نباید بیش از ۲۰ متغیر وارد کرد یعنی مثلاً ۵ یا ۶ متغیر به عنوان متغیرهای نهفته و هر متغیر ۳ تا ۴ شاخص را به خود اختصاص دهد.
تشخیص مدل یعنی آیا برای هریک از پارامترهای آزاد، میتوان یک مقدار منحصر به فرد از روی دادهها به دست آورد. براساس این تعریف سه نوع مدل خواهیم داشت:
مدلهای فرومشخص (under-identified): یک برآورد واحد برای هر پارامتر ناممکن باشد. یا به عبارتی اطلاعات مورد نیاز برای حل کردن پارامترها ناکافی باشد.
مدلهای کاملاً مشخص (just-identified): برای هر پارامتر واحد میتوان یک مقدار واحد برآورد کرد. یا به عبارتی تعداد معادلات با تعداد پارامترهای مورد تخمین برابر است.
مدلهای فرامشخص (over-identified): مدلهایی که برای هر پارامتر بیش از یک جواب دارند. یعنی تعداد پارامترهای مدل کمتر از مشاهدات است.
قاعده حسابی برای تشخیص مدل: تعداد پارامترهایی که باید برآورد شوند (پارامترهای آزاد) نباید از تعداد واریانسها و کوواریانسهای نمونه بیشتر باشد. اگر تعداد متغیرهای مشاهده شده (شاخصها) برابر P باشد، بنابراین از طریق فرمول زیر میتوان تعداد کل واریانسها و کوواریانسهای ممکن را برآورد نمود.
p × (p+1)〉 / ۲〉= تعداد کل واریانسها و کوواریانسهای نمونه
برآورد مدل شامل تکنیکهایی است که برای برآورد پارامترهای مدل استفاده میشوند. برآورد پارامترها آنقدر تکرار میشود تا مدل موردنظر در یک مجموعه نهایی از پارامترهای برآورد شده همگرا شود.
روشهای برآورد مدل
یک بخش مهم در فرایند برآورد، ارزیابی برازش مدل است. منظور از برازش مدل این است که تا چه حد یک مدل با دادههای نمونه سازگاری و توافق دارد. بدین منظور از شاخصهای برازش استفاده میشود.
در صورتی که برازش مدل قابل قبول باشد، تخمین پارامترها مورد بررسی قرار میگیرند. یعنی نتایج بخش اندازهگیری و ساختاری مدل ارزیابی میشوند. نسبت تخمین هر پارامتر به خطای استاندارد آن بوسیله آماره t نشان داده میشود. برای اینکه پارامتر موردنظر قابل قبول یا به عبارتی معنادار باشد، باید قدرمطلق مقدار t آن بزرگتر یا مساوی ۱٫۹۶ باشد. بنابراین شاخصها از دقت لازم برای اندازهگیری سازههای نهفته تحقیق برخوردارند.
گرچه انواع گوناگونی از آزمونها که به آنها شاخصهای برازش گفته میشود، در حال توسعه و تکامل میباشند اما هنوز درباره حتی یک آزمون بهینه نیز توافق همگانی وجود ندارد. تصمیمگیری درباره برازش یک مدل براساس چند شاخص و نه یک شاخص انجام میگیرد. بنابراین برای ارزیابی برازش مدل، ضروری است تعداد متنوعی از شاخصها گزارش شود. زیرا شاخص های مختلف، جنبههای متفاوتی از برازش مدل را انعکاس میدهند. برخی از این شاخصها عبارتند از:
جدول۱: انواع شاخصهای برازش مدل و مقدار مجاز آنها
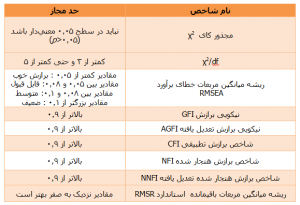
شاخصهای دیگری نیز در خروجی نرم افزار لیزرل دیده میشوند که برخی مثلAIC ،CAIC و ECVI برای تعیین برازندهترین مدل از میان چند مدل مورد توجه قرار میگیرند برای مثال مدلی که دارای کوچکترینAIC ،CAIC و ECVI باشد برازندهتر است. مقدار آماره ECVI به خودی خود قابل قضاوت نیست و برای نتیجهگیری درباره برازش مدل با مقادیر بدست آمده برای مدل استقلال و مدل اشباع شده مقایسه میگردد. مدلی که دارای کوچکترین CAIC و AIC باشد (هرچه به صفر نزدیکتر باشند)، برازندهتر است. برخی از شاخصها نیز به شدت وابسته به حجم نمونهاند و در حجم نمونههای بالا میتوانند معنا داشته باشند.
گام نهایی اصلاح مدل نامیده میشود. در صورتی که مدل از برازش ضعیفی برخوردار باشد، با استفاده از اطلاعات حاصل از خروجی برنامه، جهت بهبود مدل تغییراتی در آن اعمال میشود.
PLS یا روش حداقل مربعات جزئی (Partial Least Square) یک رویکرد واریانس محور برای مدل یابی معادله ساختاری است، این تکنیک امکان بررسی روابط متغیرهای پنهان و شاخصها (متغیرهای قابل مشاهده) را بصورت همزمان فراهم می سازد. این روش را میتوان در شرایطی که حجم نمونه کم بوده و متغیرها حالت نرمال ندارند (البته در مدلهای ترکیبی یا Formative شرط نرمال بودن حائز اهمیت نمیباشد)، به کار برد. PLS شاخصهای برازش مدل را در اختیار محقق قرار نمیدهد، بنابراین برای پیشبینی مناسبتر است.
شاخصهای برازش این رویکرد مربوط به بررسی کفایت مدل در پیشبینی متغیرهای وابسته میشوند؛ مانند شاخصهای اشتراک (Communality) و افزونگی (Redundancy) یا شاخصGOF می باشد. در واقع این شاخصها نشان می دهند که برای مدل اندازه گیری شاخصها تا چه حد توانائی پیشبینی سازه زیربنایی خود را دارند و برای مدل ساختاری، متغیرهای بیرونی تا چه حد و با چه کیفیتی توانائی پیشبینی متغیرهای درنی مدل را دارند. رویکرد واریانس محور با نرمافزارهایی مانند پی ال اس گراف (PLS Graphing)، اسمارت پی ال اس (Smart- PLS)، رپ پی ال اس (Warp PLS) و ویژوال پی ال اس (Visual PLS) قابل اجرا میباشد.
در مدلیابی معادله ساختاری به روش حداقل مربعات جزئی برخلاف روش قبلی به حجم نمونه بالایی نیاز نداریم.
چین و نیوزتد (۱۹۹۹) در یک مطالعه شبیهسازی مونت کارلو بر روی PLS با نمونههای کوچک نشان دادند که این رویکرد میتواند برای حجم نمونه ۲۰ تایی نیز اطلاعاتی درباره تناسب شاخصها فراهم آورد. با این حال با در نظر گرفتن مشکل پایداری در مقیاس بزرگ، هنوز این مدل با محدودیت هایی روبروست. با وجود اینکه PLS برای نمونههای خیلی کوچک و یا موقعی که موارد نسبت به متغیرهای مشاهده شده کمتر باشد قابل استفاده است، اما تکیه بر نمونههای کوچک میتواند نتایج ضعیفی فراهم کند. نمونههای بزرگتر، برآوردهای PLS را قابل اطمینانتر میسازد. میانگین میزان خطای مطلق در PLS با افزایش حجم نمونه کاهش می یابد. حجم نمونه کوچک برای ضرایب مسیر کوچک کافی نیست، در چنین مواردی حجم نمونه برابر با روش کوواریانس محور مورد نیاز است.
محققان دو روش را برای تعیین حداقل نمونه لازم در PLS پیشنهاد میکنند:
یکی از مهمترین تفاوتهای عمده بین مدلهای کوواریانس محور و PLS در شاخصهای انعکاسی (Reflective) و ترکیبی (Formative) میباشد. در روشهای کوواریانس محور، مدل ترکیبی وجود ندارد.
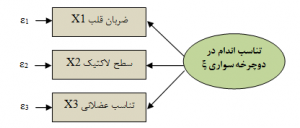
شکل ۵: نمونهای از یک مدل اندازهگیری انعکاسی
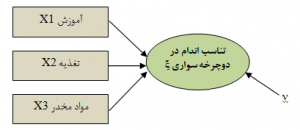
شکل ۶: نمونهای از یک مدل اندازهگیری ترکیبی
در مدل های PLS دو مدل آزمون می شود: مدلهای بیرونی و مدل های درونی. بخش اندازهگیری مدل که نمایشگر روابط بین متغیرهای پنهان با شاخصهایشان به دو صورت ترکیبی و انعکاسی میباشد، مدل بیرونی و بخش ساختاری مدل که نمایانگر رابطه بین متغیرهای مکنون است، مدل درونی نام دارد.
بررسی برازش مدلهای واریانس محور یا همان PLS در سه مرحله صورت میگیرد:
در این مرحله، روای و پایایی مدل برحسب نوع مدل یعنی انعکاسی یا ترکیبی بودن آن تعیین میشود. معیارهای ارزیابی مدل اندازهگیری در جدول زیر ارائه شده است.
جدول ۲: معیارهای ارزیابی مدل اندازه گیری (مدل بیرونی)
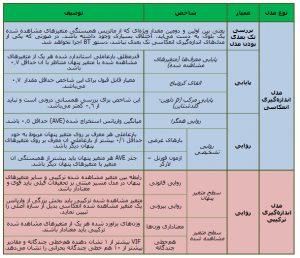
در یک مدل مسیر فقط یک مدل ساختاری وجود دارد. پس از ارزیابی برآوردهای روایی و پایایی مدلهای اندازهگیری نوبت به ارزیابی مدل ساختاری میرسد. معیارهای آزمون مدل ساختاری در جدول زیر ارائه شدهاند:
جدول ۳: معیارهای ارزیابی مدل ساختاری (مدل درونی)
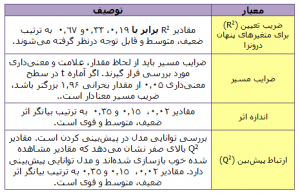
در PLS برخلاف روش کوواریانس محور شاخصی برای سنجش کل مدل وجود ندارد. البته تننهاوس و همکاران (۲۰۰۵) یک شاخص کلی به نام نیکویی برازش (GOF) را برای بررسی برازش مدل معرفی کردهاند. این شاخص را می توان با محاسبه متوسط R2 و متوسط مقادیر اشتراکی (Communality) از طریق فرمول زیر بدست آورد:
البته باید توجه داشت که این شاخص توانایی پیشبینی کلی مدل را مورد بررسی قرار میدهد. یعنی اینکه آیا مدل آزمون شده در پیشبینی متغیرهای پنهان درون زا موفق بوده است یا نه. وتزلس و همکاران (۲۰۰۹) مقادیر ۰٫۰۱، ۰٫۲۵ و ۰٫۳۶ را به ترتیب به عنوان مقادیر ضعیف، متوسط و قوی برای GOF معرفی نمودهاند.
منابع:
ممنون بسیار خوب و مختصر توضیح دادین، چند نمونه تحقیق که روش شناسی مدل سازی معادلات ساختاری را خوب رعایت کرده می تونید معرفی کنید.
با سلام
ممکن است درباره مدل ساختاری بین دو نمونه توضیح دهید؟ قسمت measurement invariance رو می خواهم بدونم. ممنون
What's up, yeah this article is actually good and I have learned
lot of things from it concerning blogging. thanks.
When someone writes an post he/she retains the image of a user in his/her brain that how
a user can know it. Thus that's why this article is perfect.
Thanks!
عرض سلام و خسته نباشید
خیلی عالی و خوب توضیح دادید و خیلی استفاده کردم با زبانی روان و گویا توضیح دادید.